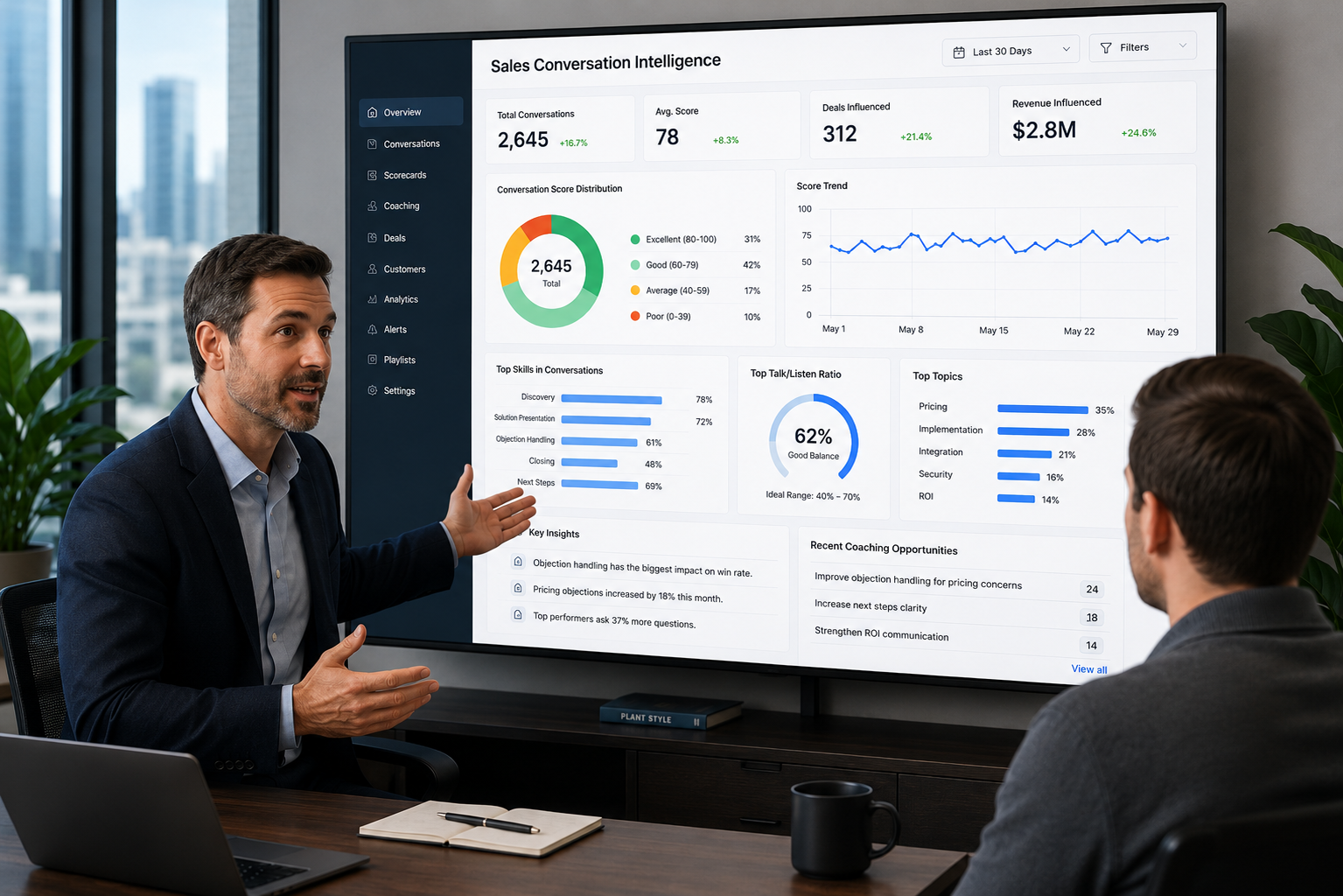
Most QA programs score calls. Few connect those scores to a training action. This guide shows QA managers how to design quality evaluation forms that make training gaps visible, aggregate scores to surface systemic weaknesses, and route findings to targeted coaching, so that low scores become learning plans instead of filed reports.
Step 1 — Design Criteria That Map to Trainable Skills
Start by listing every criterion on your current evaluation form and asking: "Is this something an agent can practice and improve?" Vague criteria like "professionalism" fail this test. Specific criteria like "uses empathy statement before addressing complaint" pass it.
Rewrite each criterion as a skill with a behavioral anchor. For example, replace "call control" with "redirects off-topic callers within 30 seconds using an approved transition phrase." Each criterion should produce a score that tells a trainer exactly what to rehearse.
Decision point: Weight criteria by business impact, not equal distribution. Compliance-adjacent criteria (script adherence, disclosure delivery) deserve higher weight than stylistic criteria (tone, pacing). A common structure: compliance 30%, resolution quality 30%, customer experience behaviors 25%, process adherence 15%.
Step 2 — Set Thresholds That Trigger Training Flags vs. Supervisor Review
Not every low score is a training issue. A single agent scoring below threshold on one call is a coaching conversation. A pattern of low scores on the same criterion across multiple calls is a training signal.
Set two threshold tiers: a coaching threshold (agent scores below 70% on a criterion in one review period) and a training threshold (agent scores below 70% on the same criterion across three or more consecutive reviews). The first triggers a one-on-one with their supervisor. The second triggers assignment to a structured training module.
Common mistake: Using a single overall score threshold instead of criterion-level thresholds. An agent can score 75% overall while failing compliance criteria entirely, masking a serious risk. Criterion-level thresholds catch this; overall scores hide it.
Insight7's QA platform lets teams configure weighted criteria with score thresholds, then automatically flags calls where individual criterion scores fall below the configured training threshold. Supervisors receive an alert with the specific criterion and the transcript evidence, not just a low number.
What methods can be used to identify gaps in employee training?
The most reliable method is criterion-level aggregation across the full agent population. Score every call on individual skills, then compare criterion averages across agents, teams, and time periods. A criterion where the team average is below 70% is a systemic gap, not an individual one.
Step 3 — Aggregate by Criterion Across the Team
Individual call reviews tell you how one agent performed. Aggregated criterion scores across the team tell you where the training program is failing everyone. Run a weekly or biweekly rollup: for each criterion, calculate the team average score.
Any criterion below 75% team average warrants investigation. Below 65% team average means the training program either never covered it effectively or the process itself has changed and training has not caught up.
Manual QA teams typically review 3 to 10% of calls, according to industry benchmarks tracked across contact center QA programs. Sampling at that rate means a team of 40 agents might produce fewer than 50 reviewed calls per week, which is not enough to detect criterion-level trends reliably. Insight7's call analytics platform covers 100% of calls and aggregates criterion scores by agent, team, and time period automatically, producing statistically reliable rollups from the first week of deployment.
Decision point: Should you aggregate by individual agent first or by team first? Both. Start with team-level aggregates to identify which criteria need attention. Then drill into agent-level data to identify whether the gap is universal or concentrated in specific agents or tenure cohorts.
Step 4 — Separate Individual Gaps from Systemic Gaps
If one agent fails a criterion, that is a coaching issue. If 50% or more of the team fails the same criterion, that is a training issue. The distinction matters because the responses are different: individual coaching works at scale for individual gaps, but it cannot fix a systemic gap that training created.
A useful heuristic: if a criterion's team average drops by more than 10 percentage points in a single month, something changed. Either the evaluation criteria changed, the product or script changed, or the inbound call type changed. Investigate before assigning training.
Common mistake: Treating systemic gaps as collections of individual coaching problems. This leads to 40 individual coaching sessions covering the same topic instead of one updated training module, which wastes supervisor time and signals to agents that the standard is arbitrary.
What is the process of determining whether training is necessary by identifying performance gaps?
Compare current criterion scores against a defined baseline, then segment results by the percent of agents affected. If a gap affects fewer than 20% of agents, targeted coaching is appropriate. If it affects more than 40% of agents, a training update is needed. The threshold between coaching and training typically sits at the 30 to 40% mark, calibrated to your team size and call volume.
Step 5 — Route Gaps to Specific Training Modules or Roleplay Scenarios
Once you have identified a systemic gap, the training assignment should name the criterion, not just the general topic. Instead of assigning "objection handling training," assign "practice module: redirecting price objections using the approved response sequence, as measured by criterion 4 on the evaluation form."
This specificity matters because it lets you measure whether training worked. Assign the module, wait 30 days, re-score the criterion across the same agent population, and compare. If the criterion average has not moved, the training content needs revision. If it has moved, you can document the gain.
Insight7's AI coaching module generates roleplay scenarios directly from the evaluation criteria that triggered the training flag. When criterion scores fall below the configured threshold, the platform auto-suggests a practice session built around that specific skill. Supervisors review and approve before assigning to agents. Fresh Prints expanded from QA to AI coaching so agents could practice flagged skills immediately after receiving feedback rather than waiting for a scheduled session.
Step 6 — Measure Whether Training Moved the Criterion Score
Training measurement starts before the module launches, not after. Pull the criterion average for the targeted skill in the 30 days before training. Record the agent cohort. After the module completes, score the same cohort on the same criterion for the next 30 days and compare.
Target a minimum 8 to 10 percentage point improvement on the targeted criterion within 60 days of training delivery. If scores do not move within that window, the gap is more likely a process problem than a knowledge problem. Re-examine whether the underlying script, tool, or workflow is creating the failure.
Decision point: Should you run a control group? For teams with 20 or more agents, yes. Assign training to half the cohort and measure criterion scores for both groups over the same period. The difference between the trained and untrained groups is your actual training effect, stripped of seasonal or volume variation.
What good looks like: Within 90 days of implementing criterion-level tracking and targeted routing, most QA managers see three outcomes: the number of repeated coaching conversations on the same topic drops by at least half, new-hire ramp time on scored criteria decreases because training is now criterion-specific, and the team average on the two or three lowest-scoring criteria rises to within 10 points of the team's top quartile.
QA managers building this process for teams of 20 or more agents can see how Insight7 handles criterion-level aggregation and auto-suggested coaching in a 20-minute session.
FAQ
What methods can be used to identify gaps in employee training?
The most reliable method for contact center training gaps is criterion-level score aggregation across the full agent population. Score every call on individual skills, calculate team averages by criterion, and flag any criterion where the team average falls below 70 to 75%. This distinguishes skills the training program never covered from skills individual agents have not practiced.
How do you measure the performance of an agent?
Measure agent performance at the criterion level, not just the overall score. An overall score of 75% can mask a failing score on a compliance-critical criterion. The most useful view compares an agent's score on each criterion against the team average for that criterion, and tracks change in those criterion-level scores over time as training and coaching are applied.
What is the 80/20 rule in call centers?
The 80/20 rule in call centers traditionally refers to answering 80% of calls within 20 seconds, which is a service-level benchmark, not a QA metric. In the context of training gaps, the relevant principle is different: in most contact centers, roughly 20% of evaluation criteria account for 80% of repeat coaching conversations. Identifying and fixing those high-failure criteria first produces the largest training impact per hour invested.
What is the best way to use quality forms to identify training gaps?
The best way is to design forms where every criterion maps to a trainable skill, set separate thresholds for coaching flags and training flags, and aggregate criterion scores weekly across the full team. Individual low scores trigger coaching. Criteria where 30 to 40% or more of the team scores below threshold trigger a training module review. Measuring criterion scores before and after training delivery closes the loop and confirms whether the intervention worked.