



In the rapidly evolving field of sentiment analysis, understanding Multimodal Sentiment Analysis is becoming increasingly essential. By integrating both voice and text, we can capture a richer, more nuanced sentiment landscape, significantly improving the accuracy of insights. Imagine reading a customer’s online review and then listening to their voice recording; the emotional subtleties highlighted in tone can reveal what words alone might miss.
Multimodal Sentiment Analysis leverages these dual channels to enhance understanding of customer emotions and intentions. By exploring how voice characteristics such as pitch and pace interact with textual content, we can better grasp the complexities of sentiment. This holistic approach not only strengthens data interpretations but also enables businesses to respond to customer needs more effectively, ultimately fostering deeper connections.
Understanding Multimodal Sentiment Analysis in Voice and Text
Multimodal sentiment analysis combines insights from both voice and text to present a richer understanding of user sentiments. It is essential to recognize that emotions conveyed through voice can be dramatically different from the meaning derived from written words. In this analytical approach, the challenge lies in harmonizing these two modalities to create a cohesive sentiment interpretation.
The role of voice brings unique features, such as tone, pitch, and rhythm, which directly influence emotional expression. Conversely, text analysis investigates structure, syntax, and word choice. Implementing a unified model requires effective techniques for capturing and preprocessing high-quality data from both sources. By understanding how to extract features from voice alongside textual sentiment, organizations can leverage comprehensive insights that lead to more informed business decisions. Ultimately, multimodal sentiment analysis enables companies to better understand their customers, driving improved engagement and satisfaction.
The Role of Voice in Multimodal Sentiment Analysis
In Multimodal Sentiment Analysis, voice plays a pivotal role by conveying nuances that text alone often misses. The way someone speaks—encompassing tone, pitch, and pace—can significantly alter the meaning of their words. For instance, a cheerful tone can enhance positive sentiments, while a shaky voice might indicate discomfort or anxiety. This complexity adds depth to sentiment analysis, making it critical to incorporate voice data alongside textual inputs.
Understanding the intricacies of voice data is essential for achieving a unified sentiment analysis model. Features like intonation can serve as indicators of emotion that accompany the spoken words. By analyzing these vocal attributes, we can better interpret the emotional state of the speaker, thus enriching the overall sentiment assessment. When combining analysis from both text and voice, we’re equipped to craft a more holistic understanding of sentiment, leading to more actionable insights.
- Key features of voice data for sentiment analysis
Voice data carries unique characteristics that significantly enhance sentiment analysis in a multimodal context. The emotional nuances conveyed through tone, pitch, and pace are crucial in interpreting intent and feeling. For instance, a raised pitch in a voice might signal excitement or surprise, while a flat tone could suggest indifference. By analyzing these vocal features, models can capture subtleties that text alone may miss.
Furthermore, voice inflections and pauses can provide context that enriches textual sentiment analysis. When combined, voice and text inputs allow for a robust understanding of user sentiment. This multifaceted approach enables analysts to not only recognize explicit sentiments but also discern underlying emotions. By leveraging these voice data features, a unified model for multimodal sentiment analysis can emerge, leading to more actionable insights and informed decision-making strategies. Integrating these diverse data forms helps create a holistic view of customer sentiment, guiding businesses in tailoring their strategies effectively.
- The impact of tone, pitch, and pace on sentiment
The way we vocalize our thoughts plays a crucial role in conveying sentiment, significantly impacting how messages are received. In Multimodal Sentiment Analysis, tone, pitch, and pace serve as vital components that enhance or detract from the conveyed emotion. A positive tone can create a sense of friendliness, while a flat or harsh tone may be interpreted as disinterest or hostility. Similarly, pitch variations can signal excitement or concern, contributing to the overall emotional context of spoken words.
Pace, too, is an essential aspect of vocal expression. Speaking too quickly can suggest anxiety or urgency, while a slower pace can indicate thoughtfulness or seriousness. By understanding these dimensions, one can construct a more accurate sentiment model that integrates both voice and text elements. This combined approach allows for a more nuanced interpretation of sentiments, offering a deeper insight into the emotional states being communicated, which is pivotal for effective interaction across various platforms.
Text Analysis in Multimodal Sentiment Analysis
Extracting sentiment from text is pivotal in Multimodal Sentiment Analysis, where the intention is to merge voice and textual data for comprehensive insights. Techniques such as natural language processing (NLP) and deep learning models are employed to decode emotions and opinions embedded in words. However, challenges remain, including the nuances of language, context, and cultural variations that can alter interpretations.
The interplay of text structure and syntax further complicates sentiment extraction. For instance, sarcasm, idioms, and word choice can significantly affect sentiment analysis outcomes. A unified approach in Multimodal Sentiment Analysis seeks to integrate both voice tone and text sentiment, enhancing the understanding of user emotions. Recognizing these complexities ensures that the model can accurately reflect sentiments across different communication modes, providing a richer, more nuanced interpretation of the user experience.
- Extracting sentiment from text: techniques and challenges
Extracting sentiment from text encompasses various techniques and confronts numerous challenges. One prevalent technique is sentiment classification, where algorithms categorize the emotional tone of a given text. This often involves assessing individual words or phrases to decipher overall sentiment. Another method is aspect-based sentiment analysis, which identifies sentiments related to specific elements within the text, providing deeper insights into consumer opinions.
However, challenges abound in this domain. The nuances of language, such as sarcasm or idioms, often complicate accurate sentiment extraction. Additionally, the context in which words are employed can drastically alter their meaning. As a result, relying solely on traditional text analysis methods can lead to misinterpretation of sentiment in many cases. Therefore, integrating voice sentiment into the analysis offers a promising avenue. By combining these approaches, a more robust understanding of sentiment can emerge, addressing many of the inherent challenges present in text-only analyses.
- The interplay of text structure, syntax, and sentiment
Text structure, syntax, and sentiment play vital roles in understanding and analyzing expressed emotions in communication. Each component interrelates to create a cohesive narrative that conveys deeper meanings. Text structure provides the framework, organizing ideas and guiding readers through the message. Syntax, on the other hand, shapes how those ideas are presented, influencing clarity and emotional impact. The combination of these elements forms the foundation for effective Multimodal Sentiment Analysis.
In this unified model, analyzing sentiment alongside voice data enhances our understanding of user emotions. Key elements include the arrangement of words, which can evoke varying sentiments depending on context, as well as the syntax utilized, which may lead to either a positive or negative sentiment analysis outcome. Finally, understanding how these factors interplay is essential for developing systems that can accurately capture and interpret emotional nuances, ultimately improving customer interactions and insights.
Building a Unified Model for Multimodal Sentiment Analysis
A unified model for multimodal sentiment analysis is essential for seamlessly integrating voice and text data, allowing for richer insights into customer sentiment. This model serves as the backbone for understanding how sentiment is expressed across different modalities. By combining these two sources of information, businesses can gain a comprehensive view of customer emotions, which may significantly enhance interaction strategies.
To build this model effectively, it is crucial to follow specific steps. First, focus on data collection and preprocessing, ensuring high-quality voice and text data are captured. This includes cleaning and labeling datasets to prepare for analysis. Next, feature extraction becomes paramount; utilizing techniques designed for both voice and text will improve sentiment detection accuracy. Finally, employing advanced tools like Natural Language Toolkit (NLTK) and IBM Watson Tone Analyzer can further streamline the building of this unified model, enabling businesses to leverage the full potential of multimodal sentiment analysis.
Step-by-Step Guide to Integrating Voice and Text Sentiment
Integrating voice and text sentiment effectively is crucial for achieving accurate multimodal sentiment analysis. The first step involves data collection and preprocessing, where high-quality voice and text data must be captured. This can include recordings, transcriptions, and relevant metadata. After collection, the data must be cleaned and labeled, ensuring that noise is minimized and sentiment-rich content is emphasized. This foundational work sets the stage for deeper analysis, enabling a clearer understanding of both verbal and non-verbal cues.
Next, feature extraction is critical. For voice, you will analyze elements like tone, pitch, and speaking rate, which can significantly influence sentiment interpretation. For text, you should focus on syntax, structure, and specific word choice. Combining these features from both modalities allows the development of a unified model that reflects a comprehensive view of sentiment. With thoughtful integration, you ensure that the model captures the nuances of human emotion, leading to insights that can drive more effective decision-making.
- Data Collection and Preprocessing
To develop an effective approach to Multimodal Sentiment Analysis, data collection and preprocessing are pivotal first steps. This phase involves capturing high-quality data from both voice and text sources, ensuring diverse samples reflecting various tones and emotions. During collection, it is essential to establish clear guidelines for data representation, focusing on context to genuinely convey sentiment.
Once the data is gathered, preprocessing begins, encompassing cleaning, labeling, and preparing datasets for analysis. Cleaning involves removing unwanted noise from audio recordings and correcting text for grammar and structure to enhance quality. Labeling is critical; assigning sentiment categories allows models to learn effectively. Finally, setting up a well-structured dataset ensures that the unified model can perform optimally. Following these foundational steps leads to more accurate and meaningful insights in sentiment analysis across voice and text modalities.
- Capturing high-quality voice and text data
High-quality voice and text data are vital for effective multimodal sentiment analysis. To begin, capturing voice data involves recording clear audio samples, ensuring minimal background noise to enhance quality. The next step is transcribing these recordings into text format, retaining the nuances of tone and pitch which contribute to the sentiment conveyed. It’s crucial to utilize accurate transcription tools that preserve emotional cues, as these aspects heavily influence sentiment interpretation.
For text data, collecting diverse written samples is essential. This includes dialogues, reviews, or social media interactions, and data should be cleaned for consistency. Proper labeling of emotional sentiment, whether positive, negative, or neutral, aids in developing more precise models. Emphasizing the integration of voice and text formats fosters a comprehensive approach for analyzing sentiments, unlocking deeper insights into user experiences and behaviors that might otherwise remain unrecognized.
- Cleaning, labeling, and preparing datasets
In the context of Multimodal Sentiment Analysis, the process of cleaning, labeling, and preparing datasets is essential for effective model training. Begin by gathering raw data, which includes both voice recordings and text inputs. The first step involves cleaning the datasets to eliminate noise, such as background sounds or irrelevant text fragments. This ensures that your model works with high-quality inputs, leading to improved sentiment accuracy.
Next, labeling the datasets appropriately is crucial. Annotate the data to reflect emotions or sentiments accurately, utilizing a clear labeling scheme. This involves categorizing voice tones or written expressions into predefined sentiment classes, such as positive, negative, or neutral. After labeling, it’s time to prepare the datasets for analysis. This may include normalizing audio files and text formatting, ensuring consistency across your inputs. With a properly cleaned, labeled, and prepared dataset, the subsequent steps in building a unified sentiment analysis model become more streamlined and effective.
- Feature Extraction
Feature extraction plays a vital role in Multimodal Sentiment Analysis, facilitating the integration of both voice and text data to derive meaningful insights. The process begins with identifying key characteristics in voice recordings, such as tone, pitch, and pace, which can significantly influence emotional interpretation. By applying various signal processing techniques, we can quantify these voice-based features, laying a strong foundation for sentiment detection.
Simultaneously, extracting meaningful features from text involves analyzing syntactic structures and semantics. Techniques like natural language processing (NLP) are essential for capturing sentiment words, phrases, and contextual meanings. This dual approach ensures that the unified model can effectively interpret sentiments across modalities, enhancing predictive accuracy. Understanding and implementing robust feature extraction techniques is crucial for creating an effective model that unifies insights from diverse data sources.
- Techniques for extracting features from voice
Extracting features from voice is essential for enhancing accuracy in Multimodal Sentiment Analysis. Various methods enable us to capture nuanced attributes that significantly influence sentiment interpretation. The first technique involves analyzing fundamental vocal qualities such as pitch, tone, and intensity. The pitch can indicate a speaker's emotional state, while tone might reveal underlying feelings that plain text cannot convey.
Another technique relies on temporal features, specifically pace and pauses in speech. A faster rate may signify enthusiasm, whereas elongated pauses could indicate hesitation or contemplation. By integrating these voice attributes with textual sentiment, practitioners can develop a more holistic understanding of sentiment across multiple contexts. Additionally, applying machine learning algorithms to voice feature subsets can uncover patterns, optimizing the performance of Multimodal Sentiment Analysis models. This collaborative approach ultimately enriches sentiment detection and boosts model robustness.
- Text feature extraction for better sentiment detection
Effective text feature extraction is crucial for enhancing sentiment detection within a multimodal sentiment analysis framework. By carefully analyzing words, phrases, and sentence structures, we can unveil underlying sentiments that may not be immediately obvious. Two key components to focus on are syntactic features and semantic meanings. Syntactic features examine the arrangement of words, while semantic analysis investigates the meaning behind the text. Together, they form a powerful approach to comprehending complex emotional cues.
Additionally, context plays a pivotal role in interpreting sentiment accurately. The co-occurrence of specific keywords and phrases can intensify or dilute the expressed emotions. Understanding these nuances enables us to capture sentiments more effectively. As we evolve our approach to combining voice and text sentiment, refining our extraction techniques will lead to a more unified and accurate model, ultimately driving better business insights and customer engagement.
Tools for Building a Unified Model
Building a unified model for multimodal sentiment analysis necessitates powerful tools and frameworks. The right tools enable the effective integration of voice and text data, ultimately enhancing sentiment interpretation. A vital first step involves data collection, where tools like Google Cloud Speech-to-Text can extract voice data with precision. Concurrently, platforms such as Amazon Comprehend assist in analyzing textual sentiment through advanced algorithms.
Feature extraction follows data collection, wherein insights from both voice and text converge. The Natural Language Toolkit (NLTK) is instrumental for text feature extraction, revealing sentiment nuances in language use. Furthermore, IBM Watson Tone Analyzer captures the emotional undertones in spoken language, enriching the sentiment analysis. Each tool provides unique strengths, fostering a holistic understanding of user sentiment across modalities. By strategically combining these resources, organizations can craft robust models that interpret sentiment more accurately, catering to diverse user experiences.
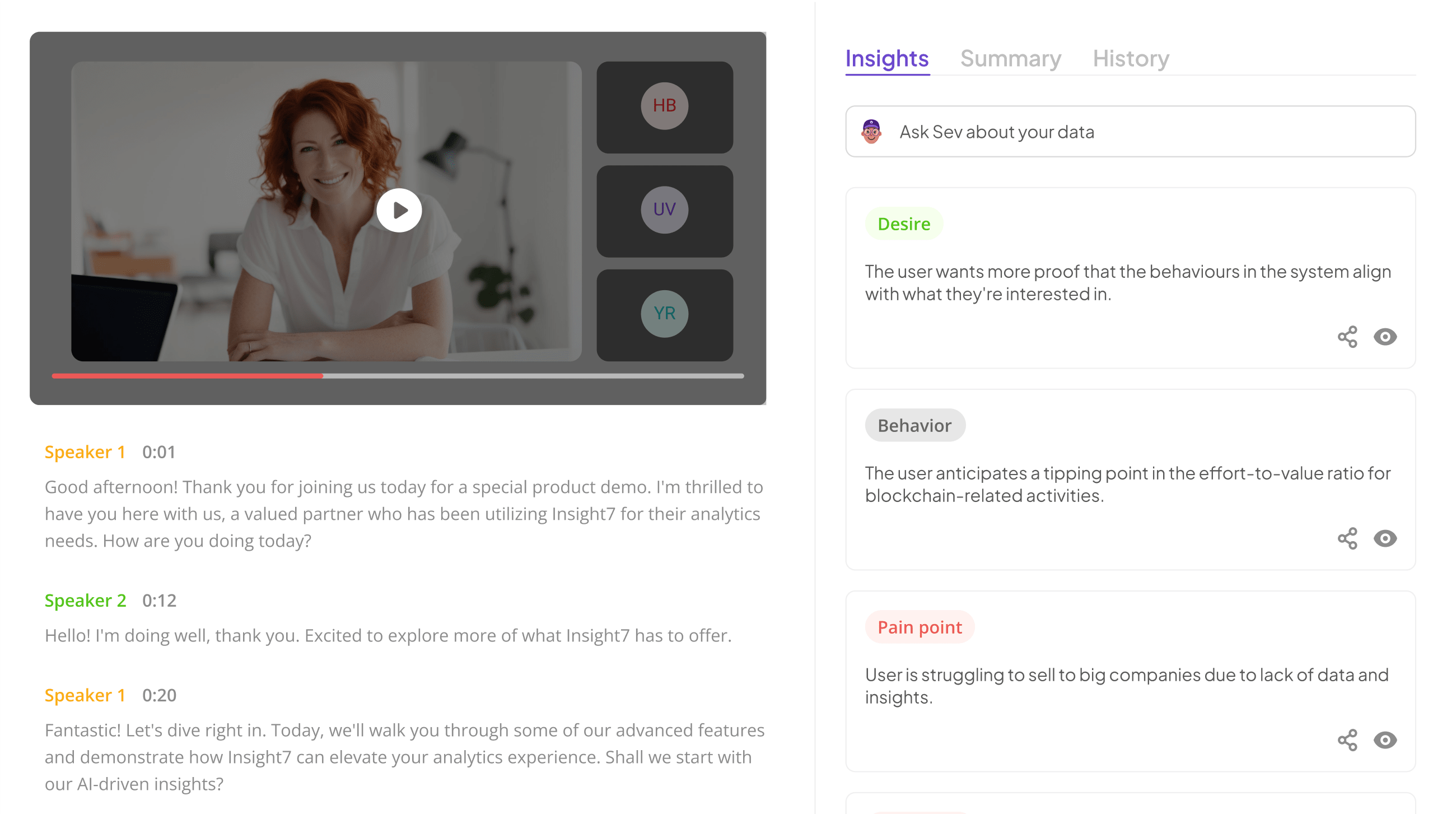
- Insight7
In Insight7, we delve into the intricacies of combining voice and text sentiment to create a unified model. This innovative approach allows organizations to gain a comprehensive understanding of customer emotions and feedback. By analyzing both vocal and written inputs, businesses can detect nuanced sentiments that audio or text alone might overlook. The convergence of these modalities enriches the data, providing a far more holistic view of customer experiences.
The integration process is multifaceted, beginning with efficient data collection. High-quality voice and text inputs must be captured, cleaned, and labeled for accurate analysis. Next, feature extraction from both formats is essential. For instance, vocal patterns and text structures need careful evaluation to reveal underlying sentiments. Finally, utilizing specialized tools like the Natural Language Toolkit or IBM Watson can streamline the development of this unified model, ensuring that your insights are actionable and relevant. By embracing a multimodal sentiment analysis approach, organizations can effectively respond to customer needs and drive strategic decisions.
Explore its features and integration capabilities
The integration of voice and text for Multimodal Sentiment Analysis opens exciting avenues for businesses to understand customer feedback. Its features are designed to make the user experience seamless and insightful. One of the primary attributes is the user-friendly interface, enabling anyone within an organization to access and analyze sentiment without requiring advanced training. This democratization of data empowers teams to generate actionable insights easily and influences decision-making processes across departments.
Moreover, the integration capabilities of such platforms can significantly enhance operational efficiency. Users can compile data from various sources, such as customer calls and textual feedback, into cohesive projects for collective analysis. This not only allows for the identification of common pain points and desires but also aids in visualizing the sentiment landscape in real-time. By implementing these features effectively, businesses will harness a more comprehensive understanding of their customer sentiments, driving informed decisions and fostering stronger customer relationships.
- Natural Language Toolkit (NLTK)
Natural Language Toolkit (NLTK) serves as a powerful resource for developing tools for sentiment analysis, especially in a multimodal context. It provides a range of libraries and functionalities that facilitate the analysis of text data. By utilizing NLTK, developers can easily preprocess and analyze linguistic elements within textual inputs, enhancing their understanding of sentiment conveyed through words. Moreover, it offers support for various natural language processing tasks, including tokenization, part-of-speech tagging, and sentiment scoring.
When integrating NLTK into a unified model for multimodal sentiment analysis, one can benefit from its extensive pre-trained models and datasets. It enables seamless extraction of sentiment from textual components, which can complement voice analysis. By combining insights from both modalities, analysts can arrive at more nuanced and accurate sentiment assessments. Exploring NLTK's capabilities is crucial for anyone looking to enhance their sentiment analysis initiatives effectively.
- IBM Watson Tone Analyzer
The IBM Watson Tone Analyzer is a powerful tool for analyzing the emotional tone of written text. It employs advanced Natural Language Processing (NLP) techniques to discern the sentiments expressed by users, leading to a better understanding of both individual and collective emotional responses. By measuring tones such as joy, anger, and sadness, this analyzer enables organizations to capture subtle nuances in communication, which is vital in the realm of Multimodal Sentiment Analysis.
When combined with voice analysis, it provides a comprehensive view of how emotions manifest in both spoken and written formats. For instance, the Tone Analyzer can enhance evaluations in customer service scenarios, allowing a business to correlate customer feedback with emotional tones detected in both text and voice interactions. This integration allows organizations to create unified models that offer deeper insights into customer feelings, drive engagement strategies, and improve service quality.
- Google Cloud Speech-to-Text
In the journey towards achieving effective Multimodal Sentiment Analysis, using Google Cloud Speech-to-Text can be a pivotal step. This tool excels at converting spoken language into readable text, bridging the gap between auditory and written data. By uploading audio files, users can easily generate transcripts, which serve as a foundation for deeper analytical insights.
Integrating this text with voice-derived sentiment creates a powerful model for understanding user emotions and reactions. Multiple features, such as tone and pitch variations, can significantly influence sentiment interpretation, allowing for richer insights. After transcription, it's crucial to analyze these texts for emotional cues, utilizing tools for further analysis. By streamlining data collection and preprocessing, Google Cloud Speech-to-Text helps in transforming raw audio into actionable insights, facilitating a comprehensive approach to sentiment analysis that effectively combines both voice and text data.
- Amazon Comprehend
Amazon Comprehend plays a crucial role in the realm of Multimodal Sentiment Analysis, offering powerful tools to enhance data insights. By utilizing natural language processing, it can analyze both text and auditory components, allowing for a more nuanced understanding of user sentiment. This integration aids businesses in deciphering customer emotions more effectively, thus refining their strategies.
When combining voice and text sentiment, it becomes essential to address how each medium contributes to the overall understanding of customer feedback. Voice tone and pitch can convey emotions that text may not explicitly express. Therefore, understanding these subtleties is fundamental to building an effective unified model. The technology not only provides automated sentiment analysis but also facilitates seamless integration with other analytical tools, helping teams to create comprehensive insights. Ultimately, this enables organizations to respond to customer needs more dynamically and empathetically, enhancing overall engagement.
Conclusion: The Future of Multimodal Sentiment Analysis
The future of multimodal sentiment analysis holds immense potential for enhancing how we interpret and respond to human emotions expressed through both voice and text. By integrating these two modalities, we can achieve a more comprehensive understanding of sentiment, leading to better customer insights and more personalized interactions. The combination allows us to capture subtle nuances, such as tone and emphasis in voice, alongside the explicit content of written text.
As technology advances, we can expect more sophisticated models that seamlessly analyze data from diverse sources. Emerging techniques in machine learning will refine our ability to synthesize these inputs, optimizing sentiment analysis frameworks. This unified approach not only improves accuracy but also paves the way for innovations in applications ranging from customer service to mental health assessments, ensuring that the future of multimodal sentiment analysis is impactful and transformative.




