



Ineffective QA metrics can often lead teams down a path of misplaced focus and misguided efforts. Many organizations rely on these metrics, believing they are indicators of performance, yet they seldom align with the ultimate goal of improving product quality. Understanding these metrics is crucial for identifying inefficiencies and fostering a culture of continuous improvement.
Common metrics such as bug count and test case execution rates may seem helpful on the surface but often lack the depth needed for meaningful analysis. This section will explore why these ineffective QA metrics can misguide teams, stifling their potential for true performance enhancement. By redefining our approach and focusing on impactful metrics, we can pave the way for more effective quality assurance practices.
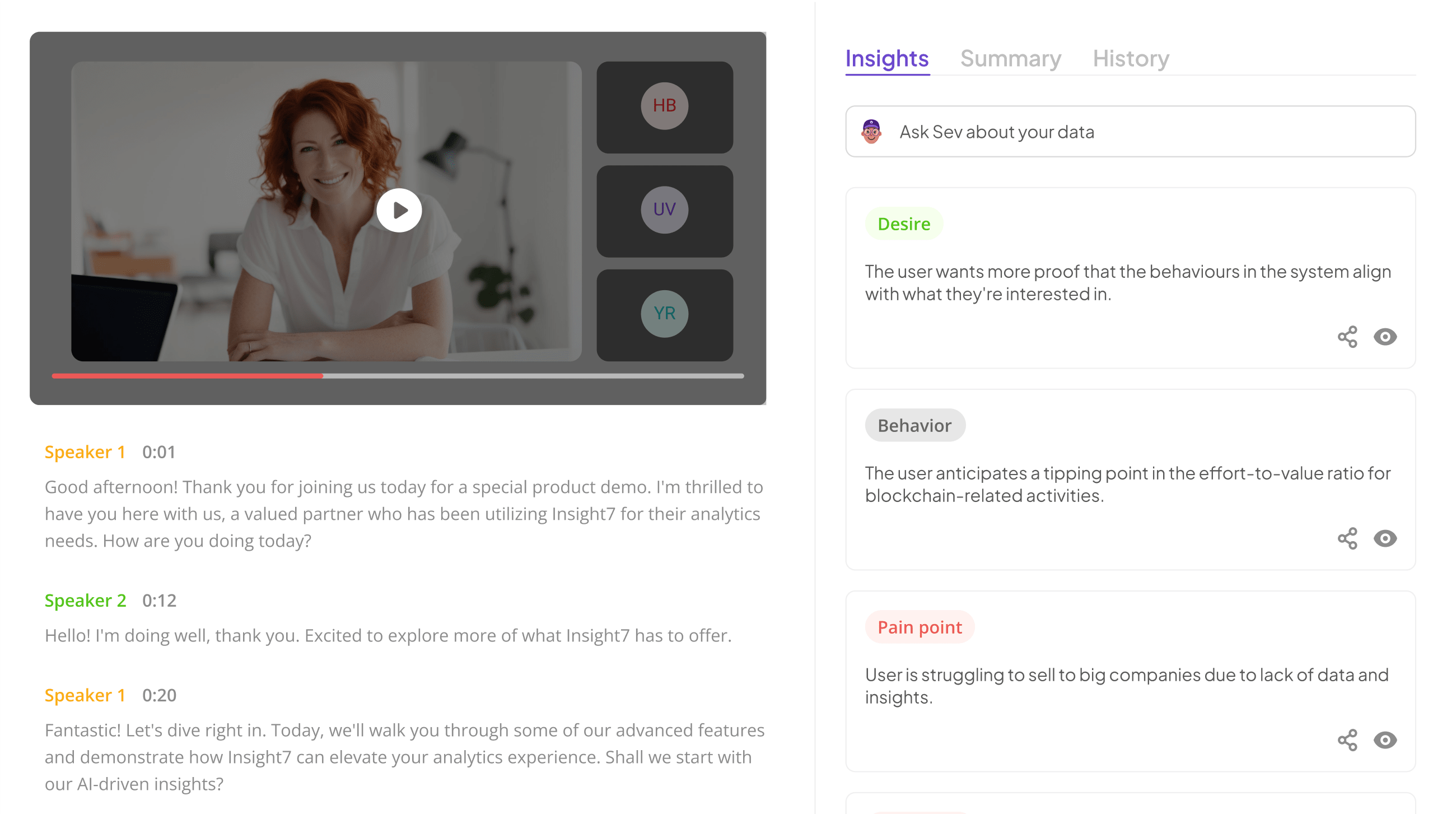
Common Ineffective QA Metrics in Performance Measurement
Common ineffective QA metrics often lead organizations down a path of confusion and misinterpretation. A prevalent example is the bug count, which merely tracks how many issues are reported without considering the severity or impact of those bugs. Focusing solely on this number can create a misleading sense of progress, as it fails to address the underlying quality of the product.
Similarly, the test case execution rate has its drawbacks. While it measures how many tests are run, it does not necessarily reflect their effectiveness or the quality of the software being developed. This metric may give a false confidence, overshadowing the real challenges in product quality. Ultimately, relying on these ineffective QA metrics inhibits meaningful insights that could genuinely enhance performance and lead to better outcomes.
Metric 1: Bug Count
When considering QA metrics, bug count often stands out as a primary measure of software quality. It simply tallies the number of identified bugs, making it an appealing metric for many teams. However, relying solely on bug count as a performance indicator can be misleading and, ultimately, ineffective. Focusing on this single metric encourages teams to prioritize quantity over quality, resulting in missed opportunities for true improvements.
Notably, a high bug count does not necessarily equate to a poorly developed product. A stable application might still register numerous bugs, often due to complex features or evolving user requirements. Instead of enhancing performance, monitoring bug count can lead to a reactive culture focused on fixing issues rather than proactively improving user experience. Consequently, teams should reevaluate their reliance on ineffective QA metrics like bug count, considering a more holistic approach to software quality that factors in user satisfaction and long-term improvements.
- Definition and Popularity
Ineffective QA Metrics are often defined as measurement tools that fail to truly reflect the quality and performance of software testing processes. One common example is the simple bug count, which might suggest a higher level of issues, but this does not necessarily indicate the overall health of the product. The popularity of such metrics stems from their ease of calculation and visibility. Yet, many in the QA community recognize that these metrics can be misleading, leading teams to focus on quantity rather than quality.
Additionally, metrics like test case execution rates can create an illusion of progress without providing real insight into product performance. These ineffective QA metrics might be favored due to their straightforward nature, but they often promote a culture of ticking boxes rather than fostering genuine improvement. Relying on these indicators can detract from more meaningful assessments that drive actual enhancements in software quality.
- Why Bug Count Doesnt Improve Performance
Focusing solely on bug count as a performance metric can be misleading and counterproductive. While it’s popular in many QA discussions, an elevated bug count doesn’t necessarily indicate poor product quality or team performance. For instance, a high number of reported bugs might arise from vigilant testing rather than systemic issues, leading teams to misinterpret their effectiveness. This can divert attention from more meaningful metrics that truly reflect the user experience and product reliability.
Moreover, prioritizing bug count often fosters a blame culture instead of promoting collaboration and innovation. Teams may feel pressured to reduce bug counts rather than focusing on creating a seamless experience for users. Ultimately, relying on bug count as a primary measure of performance is an ineffective QA metric that overlooks the nuances of software quality, detracting from initiatives aimed at genuine improvement and user satisfaction. Instead, teams should consider holistic approaches to assess software quality, focusing on the end-user experience and system reliability.
Metric 2: Test Case Execution Rate
Test case execution rate is a commonly used metric in Quality Assurance (QA) that tracks the percentage of planned test cases that have been executed during a testing cycle. While it might seem useful at first glance, this metric often fails to provide meaningful insights into overall software quality. Teams may focus excessively on boosting this rate, believing that a high percentage reflects robust testing. However, simply executing more test cases does not necessarily correlate with identifying critical defects or ensuring a product meets user needs.
Furthermore, an emphasis on execution rate can lead to superficial testing, where quantity takes precedence over quality. Teams may rush to execute tests just to achieve higher percentages, neglecting the depth and relevance of their test cases. This focus on an ineffective QA metric can ultimately mislead stakeholders about the true status of a software product and does not contribute to improving performance or quality. Instead of relying on execution rates alone, it's essential to adopt a holistic approach that emphasizes meaningful testing efforts and insights.
- Understanding the Execution Rate
Test case execution rate is a commonly monitored metric in quality assurance, yet it often fails to enhance performance significantly. Understanding this execution rate requires recognizing its limitations in effective quality assessment. While tracking how many test cases are executed may seem beneficial, simply focusing on completion rates does not account for the quality of those tests.
Focusing on ineffective QA metrics, such as execution rate, can lead to a false sense of security. A high execution rate might indicate activity, but it doesn’t guarantee that meaningful tests were conducted or that critical issues were found. Teams may rush through tests to improve numbers rather than ensuring thorough evaluations. This behavior can dilute the overall purpose of quality assurance, emphasizing the need for metrics that genuinely reflect quality and performance improvements instead of just activities logged.
- Limitations in Reflecting Quality
Many organizations rely on traditional metrics to guide their quality assurance efforts, including the test case execution rate. However, this focus can lead to significant limitations in reflecting true product quality. An overemphasis on this metric does not necessarily correlate with meaningful improvements in performance. In fact, it may foster a false sense of accomplishment that masks underlying issues.
The value of a test case execution rate is diminished when considered in isolation. This metric can encourage a tick-box approach, where quantity overshadows quality. As a result, teams may overlook critical factors like user experience and real-world functionality. Additionally, the pressure to maintain high execution rates can lead to rushed test cycles, resulting in undetected bugs or subpar features. Thus, reliance on ineffective QA metrics can hinder progress rather than propel it forward, emphasizing the need for a more holistic approach to performance measurement.
[ hfe_template id=22694]The Pitfalls of Ineffective QA Metrics
Ineffective QA metrics can create significant obstacles in improving overall performance. Many organizations rely on superficial metrics like code coverage or the percentage of automated tests, believing these figures reflect product quality. However, such metrics often mislead stakeholders and fail to address core quality assurance objectives.
For example, focusing solely on the percentage of automated tests may foster complacency, as automation does not inherently guarantee better quality. Similarly, metrics like bug counts can obscure deeper issues if the underlying causes of those bugs are not examined. Instead of relying on these ineffective QA metrics, teams should prioritize qualitative assessments and deeper insights that address the nuances of their processes and outputs. Ultimately, in-depth analysis and thoughtful metrics will foster a culture of continuous improvement, enhancing both product quality and team performance.
Metric 3: Percentage of Automated Tests
The percentage of automated tests is frequently touted as a key metric in software quality assurance. However, this focus can lead to ineffective QA metrics, generating a false sense of security regarding software performance. Many organizations celebrate high automation rates, yet automation does not guarantee that the tests are meaningful or that they cover critical functionalities. This creates a scenario where teams are busy maintaining automated tests that may not significantly impact product quality.
Focusing solely on the percentage of automated tests can obscure real quality issues. While automation can enhance efficiency, it does not replace the need for comprehensive manual testing, especially concerning user experience. It's important to remember that the essence of QA is about ensuring that products meet user needs and expectations, rather than merely executing tests. Prioritizing both quality and relevance of tests can inevitably lead to better software outcomes, instead of relying on potentially misleading automation metrics.
- Automation vs. Quality
Automation in quality assurance (QA) emphasizes efficiency but not necessarily quality. While automation minimizes human effort, many organizations lean heavily on automated test metrics without considering their true impact on product reliability. Relying solely on automated test counts can distract from genuine quality insights, leading teams to prioritize quantity over thoroughness in testing processes.
Moreover, the misconception that a high percentage of automated tests correlates with superior quality can lead to a false sense of security. Ineffective QA metrics, like automated test counts, often do not capture the intricacies of user experience or critical edge cases. The automation systems may overlook contextual nuances, resulting in missed defects. Hence, it is crucial for teams to balance automation with qualitative assessments, ensuring that quality remains a primary focus instead of merely boosting automation numbers. This balanced approach fosters a more reliable and resilient product that aligns with customer expectations.
- Misleading Insights on Performance
Ineffective QA metrics often yield misleading insights on performance that can set teams back instead of moving them forward. For instance, the percentage of automated tests executed may seem like a strong indicator of quality. However, this metric misleadingly suggests improved efficiency without truly capturing the thoroughness of testing. A higher automation rate could result in a false sense of security, masking potential gaps in test coverage or quality.
Similarly, code coverage metrics, while often celebrated, can obscure underlying issues. A project may boast a high coverage percentage, but this does not guarantee that the tested code behaves as expected across all use cases. Metrics can sometimes distort reality, leading to a misplaced emphasis on automation at the expense of deeper quality assessments. Recognizing the limitations of these ineffective QA metrics is crucial for developing a more accurate understanding of software performance and quality.
Metric 4: Code Coverage
Code coverage is often hailed as a key quality metric in software testing. It measures the percentage of code executed during testing, giving the impression of thoroughness. However, this metric can mislead teams into believing that higher coverage equates to better quality. Consequently, pursuing high code coverage may divert focus from genuinely critical test scenarios, making it one of the many ineffective QA metrics.
When teams highlight code coverage, they may overlook the value of effective test cases that actually validate business requirements. Achieving 100% coverage doesn’t automatically ensure all features function correctly or that edge cases are tested thoroughly, leading to a false sense of security. Instead of solely concentrating on coverage statistics, QA teams should emphasize comprehensive testing strategies and real-world user scenarios to enhance overall software quality. By shifting focus away from coverage alone, organizations can better allocate resources and create more robust applications.
- Defining Code Coverage
Code coverage is commonly viewed as a critical metric in software testing, often touted as a measure of reliability. It indicates the percentage of code that is exercised during testing, which might seem beneficial initially. However, relying solely on code coverage can fall into the realm of ineffective QA metrics, as high coverage does not guarantee the absence of defects or the overall quality of the software.
One major pitfall of code coverage is that it can create a false sense of security. Achieving 90% coverage may lead teams to believe their software is robust, even if the tests do not validate the core functionality. Furthermore, the quality of the tests themselves matters significantly. If tests are superficial, merely checking for code execution without assessing actual outcomes, then the purported benefits of high coverage become negligible. Ultimately, understanding these limitations is essential for QA teams striving for genuine improvement in software performance and quality.
- When Coverage Levels Are Misleading
Code coverage is often celebrated as a vital QA metric that signifies the amount of code executed during testing. However, this metric can be misleading in terms of actual software quality and performance. A high percentage of code coverage may suggest thorough testing, but it does not necessarily guarantee that all paths, conditions, or edge cases have been sufficiently validated. This reliance on numbers can lead teams to believe they are performing well when critical bugs may still exist.
Additionally, focusing solely on coverage levels can divert attention from more important aspects, such as the quality of test cases and their relevance to the application’s users. Teams may neglect the meaningful assessment of their tests, resulting in an illusion of reliability that doesn’t translate into real user satisfaction. To genuinely enhance performance, it is essential to evaluate QA efforts through a holistic lens that incorporates user impact and product functionality, rather than relying solely on ineffective QA metrics like coverage levels.
Insight and Tools for Improvement
Ineffective QA metrics often hinder progress, leaving teams puzzled about genuine quality improvements. Understanding which metrics fail to provide actionable insights is crucial for driving performance enhancement. Implementing effective tools can illuminate areas that need attention and clarify how to read and respond to the data presented.
To optimize performance, consider integrating specialized tools designed to gather and analyze relevant insights. Tools like QTest, TestRail, and Zephyr can help identify patterns and track quality over time. But it doesn’t stop there; using platforms like PractiTest can elevate your analysis further, allowing teams to explore customer feedback details and perceptions. Insights drawn from these tools can direct teams towards actionable strategies, transforming ineffective QA metrics into valuable data-driven decisions. Embracing this approach not only enhances understanding of quality but also fosters a culture of continuous improvement within your organization.
- Insight7
When evaluating QA performance, many organizations cling to metrics that, while popular, often fail to yield improvements. Ineffective QA metrics, like bug count, can create a false sense of security. Tracking sheer numbers may overlook underlying quality issues, leading teams astray from their actual performance objectives. It's crucial to recognize that these metrics often provide an incomplete picture of a product's reliability and user satisfaction.
Understanding the limitations of these metrics is essential for fostering genuine improvement. For instance, the percentage of automated tests may appear impressive, yet it tells only part of the story regarding overall testing quality. Similarly, code coverage numbers can be misleading if teams prioritize quantity over meaningful tests. Transitioning away from these ineffective QA metrics allows teams to adopt more insightful approaches, leading to tangible enhancements in both product quality and user experience.
- QTest
QTest serves as a tool many teams use in their quality assurance processes, yet it often emphasizes ineffective QA metrics. By focusing too heavily on data that does not lead to performance improvements, teams can fall into the trap of mis-measuring quality. For example, QTest might highlight metrics like test case execution rates or bug counts, but these figures may not reflect the actual user experience or product reliability.
An effective QA process requires more than metrics; it needs a deeper understanding of product functionality and user satisfaction. Relying on ineffective QA metrics can lead to complacency, where teams believe they are performing well based on numbers that don’t drive real-world improvements. Shift the focus towards metrics that correlate with user satisfaction and product success rather than solely on numbers provided by tools like QTest.
- TestRail
In the realm of quality assurance, ineffective QA metrics can often mislead teams regarding real performance improvements. TestRail, a tool designed for test case management, is commonly utilized to track various testing metrics. However, simply generating reports based on basic metrics can create a false sense of security and hinder actionable insights. Metrics gathered through TestRail, like test case execution rates or the number of automated tests, may not accurately indicate the quality or effectiveness of a product.
Instead of focusing solely on these quantitative measures, teams should emphasize the qualitative aspects of testing. For example, it is essential to analyze the context of test failures or defects rather than merely counting them. Establishing criteria based on user experience or compliance can provide deeper insights into performance and quality. Therefore, while TestRail provides valuable tracking capabilities, relying solely on ineffective QA metrics can cloud better decision-making in the testing process.
- Zephyr
Zephyr serves as a tool designed to streamline Quality Assurance processes, yet it underscores the importance of understanding ineffective QA metrics. Among the common metrics users often rely on, many fail to provide actionable insights needed to boost overall performance. For instance, metrics like bug counts might offer a glance at problems but do not explain the impact or the priority of issues, leaving teams with a superficial understanding of quality.
Furthermore, metrics derived from Zephyr can be misleading if viewed in isolation. Take test case execution rates; while they indicate activity, they do not reflect the true quality of the tests being executed. This misrepresentation can cause teams to make uninformed decisions based on data that lacks depth and clarity. Ultimately, a shift towards more meaningful metrics and insights will prove essential for driving genuine improvements in performance, moving beyond those commonly accepted yet ineffective QA metrics.
- PractiTest
PractiTest offers a unique perspective on quality assurance metrics, particularly concerning ineffective QA metrics. Many teams rely heavily on traditional metrics like bug counts and test case execution rates. However, these figures can paint a misleading picture of true software quality and team performance. When organizations focus solely on such metrics, they often overlook deeper insights that might help enhance their QA processes.
By using more meaningful performance indicators, organizations can shift their focus towards improving overall quality rather than getting lost in the fog of data. For instance, understanding the context of customer feedback may be far more valuable than merely counting bugs. Adopting a broader understanding of quality assurance allows for a more nuanced evaluation of performance, ultimately making the QA process more effective and contributing to the project's success.
The Pitfalls of Ineffective QA Metrics
Ineffective QA metrics can lead organizations astray in their performance assessments. One such metric is the percentage of automated tests. While automation is vital for efficiency, relying solely on this figure can create a false sense of security. The presence of numerous automated tests does not guarantee that essential scenarios are being covered adequately or that the software is functioning properly.
Another commonly misinterpreted metric is code coverage. This percentage indicates how much of the code is tested, but high coverage can be misleading. It often includes untested edge cases that, while mathematically covered, may not reflect the software’s actual reliability. Focusing on these ineffective QA metrics can divert attention from the crucial aspects of quality assurance, such as user experience and real-world validation. Understanding these pitfalls is key to improving overall performance and ensuring better outcomes in software development.
Conclusion: Moving Beyond Ineffective QA Metrics
In conclusion, moving beyond ineffective QA metrics is essential for fostering meaningful improvements in performance. Many organizations rely on traditional metrics that fail to provide actionable insights. Instead of focusing solely on quantity, teams should prioritize metrics that genuinely reflect quality and user experience, as these factors drive long-term success.
To achieve this, it is crucial to evaluate the metrics in use and consider alternatives that align better with specific goals. By shifting the focus from ineffective QA metrics to those that promote continuous improvement, organizations can unlock potential, enhance team productivity, and ultimately deliver better products and services.




